Dockerに見捨てられたRaspberry Pi Zero WをPodmanで復活させる

はじめに:Pi Zero Wでのコンテナ運用の現実
Raspberry Pi Zero Wは、そのサイズと価格の安さから2017年頃にちょっとしたブームになりました。実用上の制約は多いものの、今でも魅力あるマシンです。筆者も手元にPi Zero用のセンサーHATがあったため、これでセンサー値を可視化して再活用しようと考えました。
しかし、これをコンテナホストとして活用しようとすると意外な壁にぶつかります。それはDockerのARMv6サポート終了です。Docker公式は古いARMアーキテクチャのバイナリ提供を終了しており、2026年現在Pi Zero WでDockerを動かすのは茨の道です。
そこで筆者が採用したのが Podman です。これはRed Hat主導で開発されているコンテナエンジンで、デーモンレスで動作するため軽量です。何より、Debian / Raspberry Pi OSの標準パッケージとして提供されているため、apt install するだけで素直に動くのが最大の利点です。
本記事では、Dockerに見捨てられたPi Zero Wを、Podman Quadletを使って「モダンなコンテナ環境」として蘇らせる方法を紹介します。
前提条件:OSとカーネルの準備
Raspberry PiでPodmanを利用する場合、いくつか落とし穴があります。
最新のOSを利用する
Podmanの強力な機能であるQuadlet(後述)を利用するには、比較的新しいバージョンのPodmanが必要です。古いOSを使っている場合は、最新のRaspberry Pi OS(Trixie以降)をクリーンインストールしてください。
Podmanのインストール
必要な依存パッケージ(uidmap)を含めてインストールします。
sudo apt update sudo apt install podman uidmap
カーネルパラメータの変更
Raspberry Pi OSのデフォルト設定では、コンテナの実行に必要なメモリーコントローラー(cgroups)が無効化されています。これを有効にしないと、Podmanは起動してもコンテナ作成時にエラーを吐いて止まります。
/boot/firmware/cmdline.txt を開き、行末に以下のパラメータを追記して再起動します。
cgroup_enable=cpuset cgroup_enable=memory cgroup_memory=1
ランタイム:Podman Quadlet
Podmanを採用する上で、コンテナの自動起動管理をどうするかという課題があります。今回は Quadlet という機能を試してみました。
Quadletは、Systemdのユニット生成ツールです。Docker Composeに似た宣言的なファイルで構成を定義しておくと、Podmanがそれを読み取り、SystemdのServiceファイルを自動生成してくれます。
センサーからメトリクスを収集するPrometheus Exporterのような常駐プロセスの場合、OS起動と同時に確実に立ち上がってほしいものです。Quadletを使えば、コンテナを「OS標準のSystemdサービス」として扱えるため、再起動時の挙動や依存関係の定義が非常にシンプルになります。
実際の定義例(温湿度センサー監視用)を見てみましょう。
# /etc/containers/systemd/rpi-sensor-exporter.container [Container] ContainerName=rpi-sensor-exporter Image=ghcr.io/hnw/rpi-sensor-exporter:latest PublishPort=9101:9101 # センサーデバイス(I2C)のマッピング AddDevice=/dev/i2c-1:/dev/i2c-1 [Service] # コンテナが停止しても自動再起動する Restart=always [Install] WantedBy=multi-user.target
Docker Composeと記述量は大差ありませんが、[Service] や [Install] セクションからわかる通り、Systemd風のフォーマットになっています。このファイルを /etc/containers/systemd/ に配置し、デーモンをリロードするだけでサービス化完了です。
sudo systemctl daemon-reload sudo systemctl start rpi-sensor-exporter
これで systemctl status rpi-sensor-exporter でログやステータスを確認できるようになります。Podmanの理解度が高くなくても、使い慣れたSystemd管理のデーモンのつもりで使えるのは大きなメリットだと思います。
コンテナビルド:Go + ko + GitHub Actions
ランタイムが決まっても、ARMv6用のコンテナイメージをどうビルドするかという問題が残ります。
言語選定の重要性(Python vs Go)
余談ですが、今回コンテナ化したいアプリがGo製だったのはラッキーでした。
もしこれがPythonやNode.jsだった場合、ARMv6用のバイナリ(Wheel等)が提供されていないライブラリが多く、pip install のたびにC/Rustのコンパイル待ちが発生したり、クロスコンパイル環境の構築に苦戦したりしていたでしょう。
Go言語(特に CGO_ENABLED=0)の強力なクロスコンパイル機能と、後述するツールのおかげで、快適な開発環境が構築できました。
Docker build (QEMU) ではなく ko を使う
通常、x86マシン上でARMv6用イメージをビルドするにはQEMUエミュレーションを使います。しかし、わざわざエミュレーションのオーバーヘッドをかけてビルドするのは効率的ではありません。
そこで、Go製のイメージビルドに ko を採用しました。
コンテナイメージの実体は、実は単なるファイルのアーカイブ(tar)とメタデータです。ko はこの点に着目し、Goでクロスコンパイルしたバイナリを、Dockerデーモンを介さずに直接イメージ形式のアーカイブとして出力するというアプローチを取っています。
QEMU環境下で COPY や RUN を実行してファイルシステムを構築するのではなく、単にバイナリを生成してtarで固めるだけなので、CPU本来の速度でARMv6用イメージを生成できます。
ベースイメージをAlpineに固定する
ko のデフォルトベースイメージはARMv6をサポートしていません。そのため、.ko.yaml で明示的に Alpine Linux を指定し、かつ CGO_ENABLED=0 で静的リンクバイナリを作成するようにします。
# .ko.yaml defaultBaseImage: alpine defaultLdflags: - -s - -w
GitHub Actionsでの設定
この構成はCI/CDとも相性抜群です。GitHub Actions上で ko を走らせれば、シンプルな記述でマルチアーキテクチャビルドが完了します。
以下は実際に使用しているWorkflowの抜粋です。--platform に linux/arm/v6 を指定しているのがポイントです。
- name: Setup Go uses: actions/setup-go@v5 with: go-version: '1.25' - name: Install ko uses: ko-build/setup-ko@v0.6 - name: Build and Push run: | ko build . \ --bare \ --platform=linux/amd64,linux/arm64,linux/arm/v7,linux/arm/v6 \ --tags=latest \ --image-label org.opencontainers.image.source=https://github.com/${{ github.repository }} env: KO_DOCKER_REPO: ghcr.io/${{ github.repository }} CGO_ENABLED: 0
これにより、GitHubにコードをPushしたら自動的にPi Zero Wで動くイメージが生成されるようになります。
おわりに
シングルコア・メモリ512MBのPi Zero Wにおいて、コンテナ運用は非現実的だと思われている方も多いのではないでしょうか。しかし、 Podman とGo製アプリのコンテナの組み合わせであれば、問題なく動作することが分かりました。
実際に運用中のメトリクスを見ても、リソース不足で落ちることもなく安定しています。皆さんも昔買ったPi Zero Wを引っ張り出してみてはいかがでしょうか。

自宅でAnsibleするなら教科書通りの構成を捨てよう
本稿は「KLab Engineer Advent Calendar 2025」の25日目です。記事を書いてくださった皆さん、お疲れさまでした!
はじめに
私は過去に何度か「自宅のマシン管理にAnsibleを使うぞ」と挑戦しては敗れ去ってきました。定着しなかった一番の理由は「オーバーテクノロジーでコスパが悪いから」です。同じ経験をした人も多いのではないでしょうか。
しかし、試行錯誤の末、自宅のマシン管理に最適な「ホスト指向Ansible」に辿り着きました。本稿ではその概要を紹介します。
なぜ自宅環境だとAnsibleはコスパが悪いのか
Ansibleを知らない人向けに簡単に説明すると、Ansibleは複数マシンのセットアップ手順をコード化する有名OSSです。典型的な教科書通りのAnsibleでは、次のような概念で各ホストを管理します。
graph LR
%%{init: {'theme': 'base', 'themeVariables': { 'lineColor': '#888', 'edgeLabelBackground':'#bbb' }}}%%
Host((ホスト)) -->|N:N| Group[グループ]
Group -->|N:N| Role[Role]
Role -->|1:N| Task(Task)
ソフトウェア1個をセットアップする手順のかたまりをRoleと呼びます(例:「nginx」や「MySQL」)。グループは「Webサーバ」「DBサーバ」などホストの役割を定義します。
企業のインフラなら「同じ構成のWebサーバを10台作る」ためにグループは必須です。しかし、自宅では同じ役割のマシンが複数必要になることはまずありません。それぞれのマシンが異なる役割を持つ自宅環境で、グループをどう扱うかは悩みの種になります。
また、N:N関係を表現するために設定ファイルの階層が深くなり、冗長性が高くなる点も、個人環境での取っつきにくさの原因と言えるでしょう。
自宅で使うなら「ホスト指向Ansible」
私の出した結論は、自宅ではグループの概念は不要と割り切り、下記のスタイルで運用するというものです。
%%{init: {'theme': 'base', 'themeVariables': { 'lineColor': '#888', 'edgeLabelBackground':'#bbb' }}}%%
graph LR
Host((ホスト)) -->|1:N| Role[Role]
Role -->|1:N| Task(Task)
バッサリと中間層を削り、N:N関係も排除しました。 このアプローチにより、1ホストに対応する設定ファイルは1ファイルのみ(host_vars)となり、見通しが劇的に良くなります。
具体的には、以下のように各ホスト変数ファイル内で「適用したいRoleのリスト」を定義するような方針です。Ansibleに挫折した人でも、このファイルならメンテナンスできるイメージが湧くのではないでしょうか。
--- apply_roles: - system_bootstrap - rsyslog - prometheus.prometheus.node_exporter - name: geerlingguy.docker become: true - docker_apps docker_daemon_options: log-driver: "journald" log-opts: tag: "{{ '{{' }}.Name{{ '}}' }}" docker_apps: - dockge - alloy
site.yml を汎用の実行エンジンにする
この構成を実現する最大のポイントは、メインのPlaybookである site.yml に具体的な構成情報を一切持たせないことです。
通常のPlaybookではグループごとに対応するRoleを記述しますが、この構成では全てのホストに対して「変数 apply_roles に書かれたRoleを順番に実行する」という処理だけを行います。
--- - name: Apply dynamic roles to hosts hosts: all tasks: - name: Include roles based on host variable ansible.builtin.include_role: name: "{{ role_item.name | default(role_item) }}" apply: become: "{{ role_item.become | default(false) | bool }}" tags: "{{ role_item.tags | default([]) }}" loop: "{{ apply_roles }}" loop_control: loop_var: role_item tags: - always
これにより、新しいサーバーを追加する際も site.yml を編集する必要がなくなり、新しいホスト用の host_vars ファイルを一つ作るだけで作業が完了します。
汎用Roleで省コストなコンテナ配置
私が過去にAnsibleに挫折した頃は、個人のマシン管理にDockerは大げさすぎると思っていました。特に自分しか使わない自作デーモンをコンテナ化するのはコスパが合わないと感じていました。
その考え方を変え、今回はコンテナ化できるものは全てコンテナ化するようにしました。また、コンテナ管理のための汎用のコンテナデプロイRole(docker_app)を用意しました。
この Role は、docker_apps変数で渡されたアプリ名(例: alloy)に基づいて、以下の処理を自動で行います。
- 設定ファイルの探索:
host_varsまたは Role 内のテンプレートからdocker-compose.ymlやその他設定ファイルを探す。 - 配置: サーバー上の所定のディレクトリ(例:
/opt/stacks/alloy)にファイルを配置。 - 起動: docker compose up -d を実行。
ビルド済みコンテナさえあれば、docker-compose.yml を書いて host_vars に1行追加するだけでコンテナを増やせるので、試行錯誤が多い自宅環境に非常に向いています。
まとめ
自宅でのAnsible運用が現実的になったよ、という話を紹介しました。
今回の説明用Ansibleプロジェクトは以下のURLで公開しています。過去に自宅Ansibleに挫折した方は参考にしてみてください。
本稿の取り組みで感じたのが、AI時代になって「コスパ」の考え方が以前と変わっているんじゃないか?ということです。人は楽をしたい生き物なので、優れているけど複雑すぎるものを使い続けることはできません。しかし、AIの助けで入門が楽になったり、楽に運用する方法を一緒に考えたりできるようになり、以前ならコスパが合わなかった技術が今なら採用できる、ということが今後増えていくのではないでしょうか。
Grafana CloudのFree tierでアラート通知に画像を添付する方法
この記事は「KLab Engineer Advent Calendar 2025」の1日目です。初日から少々ニッチな小ネタです。
Grafana CloudのFree tierが大盤振る舞いすぎる
突然ですが、みなさんGrafana Cloud使ってますか?Grafana Cloudは、Grafana Labsが提供するフルマネージドのオブザーバビリティサービスです。私は自宅サーバーやIoTデバイスのモニタリング・アラーティングに活用しています。
例えば、自宅のCO2濃度の推移を可視化し、次のようなグラフを作成することが可能です。

Grafana Cloudの大きな特徴は、Free tierの充実ぶりです。2025年12月現在、クレジットカードの登録不要で以下のリソースを利用できます。
- Metrics: 10k series(Prometheus等のメトリクス)
- Logs: 50GB(Loki)
- Traces: 50GB(Tempo)
- Users: 3ユーザーまで
- データ保持期間: 14日
自宅の環境モニタリングや個人の小規模な開発用途であれば、10k seriesのメトリクスや50GBのログ容量は十分すぎると言えるでしょう。無料で構築できるモニタリング環境として、私の知る限り最強の選択肢の一つだと思います。
アラート通知を設定する
Grafana CloudのFree tierでは最大100個までアラート通知を設定することができます。例えば「CO2濃度が1000ppmを超えたら通知する」という設定は、以下の手順で行います。
- Alerting > Alert rules に移動し、「New alert rule」を作成します。
- クエリとアラート条件を設定します(例:
avg(switchbot_co2{ })、Is above 1000)。 - Folder と Evaluation behavior を設定します。
- Contact points でSlackなどの通知先を指定します。
- Alert ruleの設定画面下部にある「Link dashboard and panel」で、このアラートに対応させるダッシュボードとパネルを選択します。
- 通知にグラフ画像を添付するには、その元となる描画情報が必要なため、必ずダッシュボードと紐付ける必要があります。
これでアラート通知自体は届くようになります。しかし、デフォルトの状態ではテキストのみの通知となってしまい、グラフ画像は添付されません。
通知に画像を添付するにはサポートへの問い合わせが必要
アラート通知にグラフ画像を添付するには、さらに以下の2つの準備が必要です。
後者のImage Renderer有効化は管理画面では設定できず、サポートチケットを発行して依頼する必要があります1。
私は下記のような問い合わせを出したところ、数時間で有効化されました。
件名: Request to enable "Images in notifications"
本文:
I would like to enable "Images in notifications" for my alerts. Please enable the image rendering feature for my instance. Instance Name: [あなたのインスタンス名].grafana.net Information: - I am using the Free tier account. - My Alert Rule is linked to a Dashboard UID/Panel ID correctly. - I have configured the Slack App with files:write permissions.
チケットのタイプ: Billing/Cancellation (※機能追加の依頼に適した項目が見当たらないため、一番近い選択肢で送ります。)
サポートから「有効化したよ!」と返信が来たら、わざとアラートを発生させて確認しましょう。Slackで下記のようなグラフが確認できるようになります。
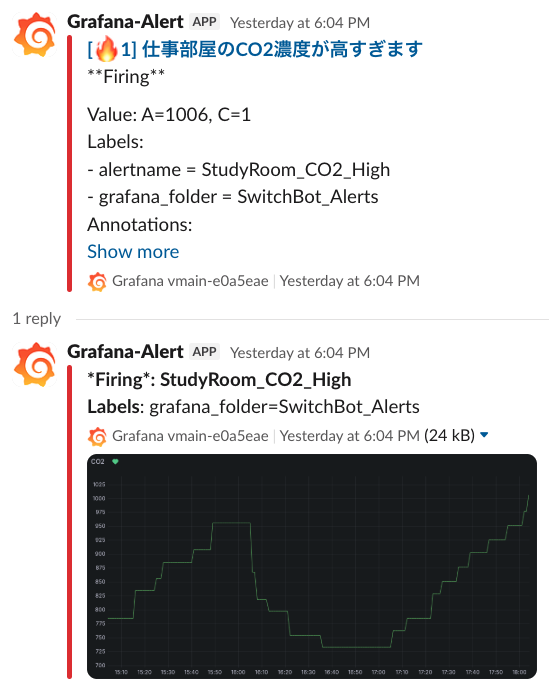
通知画像のタイムゾーンと期間を最適化する
Slackへの画像添付には成功しましたが、デフォルト設定のままだと「時間がずれている(UTC表示)」「グラフの期間が広すぎて直近の変化が分からない」といった点が気になるかもしれません。
ダッシュボードで次の設定を行うことで、見やすい通知画像に調整できます。
1. グラフの標準時をJSTにする
ダッシュボード上部の「Edit」「Settings」「General」から、Timezoneの設定を変更します。
- Time zone:
DefaultではなくAsia/Tokyoを指定。
2. デフォルトの時間幅を調整
アラート発生時の状況を把握するには、あまりに長い期間の画像だと直近の変化が潰れて見えなくなってしまいます。
- ダッシュボード右上の時間選択で、適切な期間(例: Last 3 hours)を選択します。
- その状態でダッシュボードの「Save」ボタンを押し、「Update default time range」 にチェックを入れて保存します。
これで、アラート通知時に生成される画像が「JST表示」かつ「直近3時間」のグラフになり、Slack上でパッと見ただけで状況が把握できるようになります。
まとめ
Grafana Cloudでアラート画像添付を使いたい場合、サポートチケット経由で依頼する必要があります。Free tierであってもこのリクエストが通る2ことは、意外と知られていない情報だと思うので記事にしてみました。
サポートチケットを発行するのは心理的ハードルがあるかもしれませんが、一度設定してもらうとモニタリングの快適性が大きく向上します。ぜひ、ご自身の環境でも試してみてください。
- Use images in notifications を参照↩
- 少なくとも私の場合はリクエストが通りました。公式ドキュメントにはプランによる制限の明記はありませんが、リソースを消費する機能のため、将来的にポリシーが変わる可能性があります。↩
switchbot-actionsではじめる最小構成のIoT
SwitchBotのセンサーデバイス(人感センサーやCO2センサーなど)は、エンジニア視点で見てもハードウェアとしての完成度が非常に高いガジェットです。コンパクトで省電力、かつデバイス単体であれば価格も手頃です。
しかし、これから試そうと思うエンジニアにとって、一つだけ「心理的なハードル」が存在します。それは、公式アプリでの自動化やクラウド連携を行うために、原則として SwitchBotハブ(定価4,000円程度)が必須となる点です。
「データ取得のためだけに専用ハブを買うのは気が引ける……」 「CO2センサーには興味があるので、まずは少し遊んでみたいな……」
そう考える方におすすめしたいのが、拙作の switchbot-actions です。これを使えば、専用ハブを介さず、デバイス1台からSwitchBotの可能性を引き出すことができます。
switchbot-actionsを使うメリット
switchbot-actions は、SwitchBotデバイスを制御・自動化するためのOSSです。このツールを導入する主なメリットは以下の3点です。
1. ハブ不要でスモールスタートが可能
switchbot-actions は、PCやRaspberry Piに搭載されたBluetooth機能を使い、デバイスと直接BLE通信を行います。つまり、一般的なSwitchBotユーザーが利用する公式の「SwitchBotハブ」を購入する必要がありません。 これはエンジニアにとって大きなメリットと言えるでしょう。
「まずはCO2センサーだけ購入して、手元のRaspberry Pi(ラズパイ)で値を取りたい」という場合でも、最小の手間とコストで始められます。
2. YAMLひとつでロジックを記述できる
公式アプリの自動化機能も進化していますが、複雑な条件分岐(条件Aかつ条件Bの時だけ……等)や、任意のSlack WebhookへのPOST送信といった柔軟な外部連携まではカバーしきれていません。
switchbot-actions では、動作のすべてを1つの config.yaml に記述します。
「温度が28度を超えたら」「開閉センサーのボタンが押されたら」といったトリガー条件や、Webhook、シェルコマンド実行といったアクションを、コードベースで柔軟に定義できます。
3. データを自分のものにできる
センサーの現在値を確認するだけでなく、時系列データとして蓄積・可視化したくなるのがエンジニアの性ではないでしょうか。 このツールでは Prometheus Exporter 機能を実装しています。設定を一行追加するだけで、Grafana等を用いて室温や湿度を簡単にグラフ化できるようになります。
実践:CO2センサーで作る「換気アラート」
では、実際に switchbot-actions を使って、実用的なシステムを作ってみましょう。
テーマは、在宅勤務の生産性を守る「CO2換気アラート」です。
やりたいこと
- 機材: SwitchBot CO2センサー、Raspberry Pi 3(BLEを搭載していればPCやMacでも動作します)
- 条件: CO2濃度が1000ppmを超えたら
- 動作: Slackに「換気してください」と通知を送る
設定ファイル (config.yaml)
やることはシンプルです。config.yaml を作成し、以下のように記述します。
# config.yaml # 1. デバイスの定義 (MACアドレスはデバイス裏面、またはスキャンコマンドで確認) devices: my-co2-meter: address: "AA:BB:CC:DD:EE:FF" # 2. 自動化ルールの定義 automations: - name: "換気アラート" # 頻繁に通知が来ないよう、一度発火したら1時間は静かにする cooldown: "1h" # トリガー設定 (IF) if: source: "switchbot" device: "my-co2-meter" conditions: # CO2濃度が1000ppmを超えたら発火 co2: "> 1000" # アクション設定 (THEN) then: - type: "webhook" url: "https://hooks.slack.com/services/YOUR/SLACK/WEBHOOK" method: "POST" payload: text: "🚨 *換気アラート* 🚨\n現在のCO2濃度は *{co2}ppm* です。窓を開けましょう!"
解説
- 動作概要: ラズパイが直接CO2センサーのBLEアドバタイズ信号を拾い、YAMLの条件 (
co2: "> 1000") に合致した瞬間、インターネット経由でSlack APIを叩きます。 - プレースホルダー:
{co2}と記述するだけで、センサーから取得した実際の値をメッセージに埋め込めます。 - cooldown: 「1001ppm」と「999ppm」を行き来するたびに通知が来ると、実運用ではノイズになります。
cooldown: "1h"を設定すれば、「一度通知した後は1時間何もしない」といった制御も設定ファイルだけで完結します。
これだけの記述で、自分だけの換気アラートシステムが完成しました。
筆者はほぼ同じ仕組みを実用しています1。在宅勤務中に部屋を閉め切っているとCO2濃度が上がりやすいため、興味を持った方はぜひ試してみてください。 SwitchBot CO2センサーは少々値が張りますが、CO2センサー(NDIR方式)の部品単価自体が高価であることを考えると、完成品としてこの価格はコストパフォーマンスが高いと言えます。

導入手順
導入には Python 3.11 以上 が動く環境が必要です。システム環境を汚さないよう、 pipx でのインストールを推奨します。
1. インストール
# pipxが未インストールの場合はまずインストール # (Ubuntu/Debian系の場合: sudo apt install pipx) pipx ensurepath # switchbot-actionsのインストール pipx install switchbot-actions
2. デバイスのスキャン
まずは設定ファイルなし、かつデバッグモードで起動し、ラズパイからセンサーが見えているか確認します。
# -vv (verbose x 2) をつけるとDEBUGログが表示され、受信したBLEデータが見えます # Bluetoothへのアクセス権限が必要な場合があります switchbot-actions -vv
ログに Received advertisement from... と表示され、手持ちのセンサーのMACアドレスが見つかれば準備完了です。ここで確認したアドレスを config.yaml に記述してください。
3. 起動
先ほど作成した config.yaml を保存し、指定して起動します。
switchbot-actions -c config.yaml
これだけでラズパイがスマートホームハブになりました。
本格的に運用する場合は、リポジトリのドキュメントを参考に systemd や Docker で常時稼働させてください。筆者の自宅では半年ほど動き続けています。
まとめ
SwitchBot製品は、ハードウェアとしての完成度だけでなく、ユーザーが自由に遊べる余地が広い点も魅力です。switchbot-actions がそのハードルをさらに下げるツールになればと願っています。
- ハブを買わずに、センサー1個から始められる
- YAMLでロジックを記述できる
- 必要ならGrafanaで可視化できる
まずはデバイスひとつから、手作りIoTの実験をしてみてはいかがでしょうか。特に入門用として、以下の3つは安価でおすすめです。
 熱中症対策")


- 筆者はGrafana Cloudで可視化・アラーティングをして、Slack通知しています。設定は面倒ですが、Slackにグラフ画像を出せるのがメリットです。↩
10年ぶりにPHP勉強会でLT発表してきました
先日、10/29に開催された「第180回PHP勉強会」にてLT発表をさせてもらいました。
なんと、私のPHP勉強会での発表は10年ぶりでした(前回は第94回だったようです)。最近はPHPを直接書く機会は減ってしまいましたが、私にとっても思い入れのある勉強会で、久々に参加できて良かったです。
当日は「業務でAIを使いたい話」というテーマで、AIコーディング支援の理想と現実、そしてAIの能力を引き出すための環境整備についてお話しさせていただきました。
AI活用の実態:アンケート結果「導入9割」vs「活用1割」
当日、会場の参加者の皆さんに簡単なアンケートを実施しました。正確な数字ではないですが、私のパッと見の印象では次のような結果でした。
- Q1: 会社で有償のAIを導入してますか? → はい:9割
- Q2: 業務のコード、AIに書かせてますか? → はい:4割
- Q2b: 9割方AIに書かせてます? → はい:1割
「有償AIの導入率」は9割と非常に高い一方で、そのうち「業務コードの9割をAIに書かせている」と回答したのはわずか1割でした。プロトタイピングや使い捨てのコード作成にAIを活用できていても、業務コードへの適用はまだこれから、という方が多数派と考えて良さそうです。
これに対してどう立ち向かっていくべきかというお話をさせてもらいました。発表資料は下記です。
活用が進んでいる会社の話も聞けた
勉強会では、参加者の方々からリアルなAI活用事例も聞くことができました。
といった声が印象的でした。
私自身、AI適性の観点でPHPはNode.jsやPythonに比べて一歩劣る印象を持っていましたが、今回の勉強会を通じて、言語の適性以上に「AIフレンドリーな環境整備」の方が、AI活用の成否に大きく効くのではないかと感じました。勉強会に参加すると生きた話が聞けるのが本当に良いですね。
おわりに
それにしても、PHP勉強会って20年続いてる勉強会なんですよね。これは本当にすごいことだと思いますし、これまでバトンをつないできてくださった運営スタッフの方々には感謝しかありません。
また、勉強会に行くと尖った発表が聞けるのも本当に楽しいですね。私は@nsfisisさんの発表「浮動小数点数の半開区間で一点を指定する」が聞きたくて参加を決めたところもあるのですが、期待以上の内容でした。浮動小数点数のビットパターンが上手い設計になっていてnextUpとnextDownの実装が比較的簡単(要約)という話を発表後に聞けて、とても興味深かったです。
また昔のように勉強会に参加したいな、と思える機会でした。スタッフの皆さま、参加者の皆さま、ありがとうございました!
「毎日が祝日カレンダー」を作りました
みなさん連休を楽しんでいますか?4連休って長いようで短いですよね。「毎日が祝日だったらいいのに…」なんて、小学生の頃はよく考えていました。
そんな子供の頃の夢を、テクノロジーの力で形にしてみました。その名も「毎日が祝日カレンダー」です!
このサイトでは世界198の国と地域1の祝日を1つのカレンダーにまとめて表示しています。ぜひサイトを覗いてみてください。カレンダーのほとんどの日が赤く染まっています。

これで毎日がお休み気分…となるかはわかりませんが、世界の祝日をパラパラ眺めているだけでも異文化に触れる面白さがあって、意外と楽しいのでオススメです。
カレンダーを支える技術:date-holidays
このカレンダーの祝日の表示はJavaScriptのdate-holidaysというライブラリで行っています。これは過去の記事「date-holidays という祝日ライブラリが良い意味で狂っていた」でも紹介したもので、世界中の祝日をYAMLで定義している野心的なプロジェクトです。
ただ、このライブラリの素晴らしさにも関わらず協力者が少ない状況で、一部の祝日について不正確だったり最新の法改正に対応できていなかったりします。
私も微力ながら、アルゼンチンやサウジアラビアの祝日についてコントリビュートしていますが、もし海外在住の方や特定の国の祝日に詳しい方がいらっしゃれば、情報の修正や追加にご協力いただけると嬉しいです。
世界の休日・祝日の豆知識
今回のカレンダーを作る中で、いくつか面白い発見があったので紹介します。
①「日曜日=休日」とは限らない
このカレンダーでは、祝日ではない日曜日も赤く表示しています。これは多くの日本人や欧米人にとって自然なことだと思いますが、世界に目を向けると日曜日が平日(労働日)の国も存在します。
例えばサウジアラビアやバングラデシュでは金曜と土曜が休みの週休2日制を採用しています2。こうした国の人々は日曜だけを特別扱いすることに違和感を覚えるかもしれません。

全世界の人が納得するカレンダーを作るのは意外と難しいですね。
いっそ「世界中の誰かが休んでいる日カレンダー」というコンセプトにして、金・土・日を全部赤く塗りつぶしてしまえば、それはそれで面白いかもしれません。
②独自の暦に紐づく祝日計算が大変すぎる
世界には、私たちが普段使っているグレゴリオ暦とは異なる、独自の暦に基づいて日付が決まる「移動祝日」がたくさんあります。
特に宗教関連の祝日は太陰暦や太陰太陽暦など古い暦に基づいていることが多く、毎年日付が変わります。
例えば、タイなどの上座部仏教国で見られる「ウェーサーカ」(ブッダ生誕、悟り、入滅の日)の祝日は、タイ太陰暦の6月の満月の日に行われます。
こうした移動祝日の日付を将来にわたって正確に計算するには、それぞれの古い暦をプログラムで再現する必要があり、なかなかハードルが高いのが実情です。
date-holidaysライブラリも多くの暦に対応している3のですが、タイ太陰暦の計算ロジックはまだ実装されていません。
また、インドではヒンドゥー教の祝日の基準となる暦が地域ごとに複数4存在するため、インドの祝日すべてに正確に対応しようとするとメチャクチャ大変です。
まとめ
- 全世界の祝日を1つにまとめた「毎日が祝日カレンダー」を作りました。
- このカレンダーはJavaScriptライブラリdate-holidaysで実現していますが、祝日情報の更新や複雑な暦の対応に改善の余地があります。
- 特定の国の祝日事情に詳しかったり、古い暦の知識をお持ちの方がいらっしゃいましたら、date-holidays プロジェクトに情報提供やPull Requestいただけると嬉しいです!
Cloudflare Email Routingのログ確認がGrafana Cloudで快適になった話
Cloudflare Email Routingのダッシュボードの不満点を解決したい
Cloudflare Email RoutingはCloudflareに預けているドメイン宛てのメールを転送してくれるサービスです。無料で提供されているので、独自ドメインの管理者にとってありがたいサービスだと思います。
ただ、Cloudflare Email Routingを利用している中で、私は以下のような不安を感じていました。
- 転送されなかったメールが本当に不要なものなのか把握できていない
- 転送を一段はさむことで、DKIM署名の不整合が起きるなど新たなトラブルがあるのではないか
これらの課題に対してCloudflare標準のダッシュボードの機能は十分とは言えません。特にメール転送の成功・失敗のログが過去24時間分しか見えない1のは制約として大きく、何かトラブルがあっても「今週末に調べよう」ということができません。せめて7日間は見せてほしいですね。
このログをGrafana Cloudに転送したら便利になりました、というのが本稿で紹介する内容です。各サービスの無料枠の範囲で実現できますので、私と同じ不満を持っている方は是非お試しください。
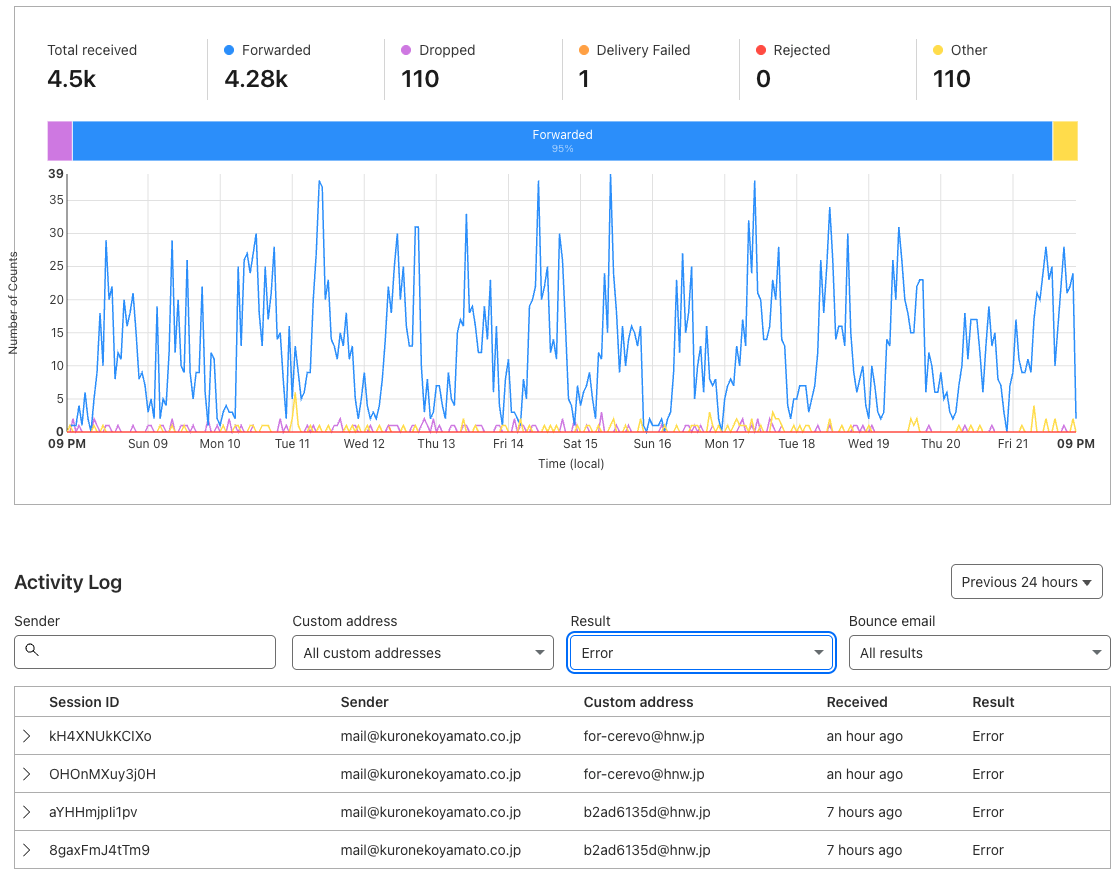
作ったもの
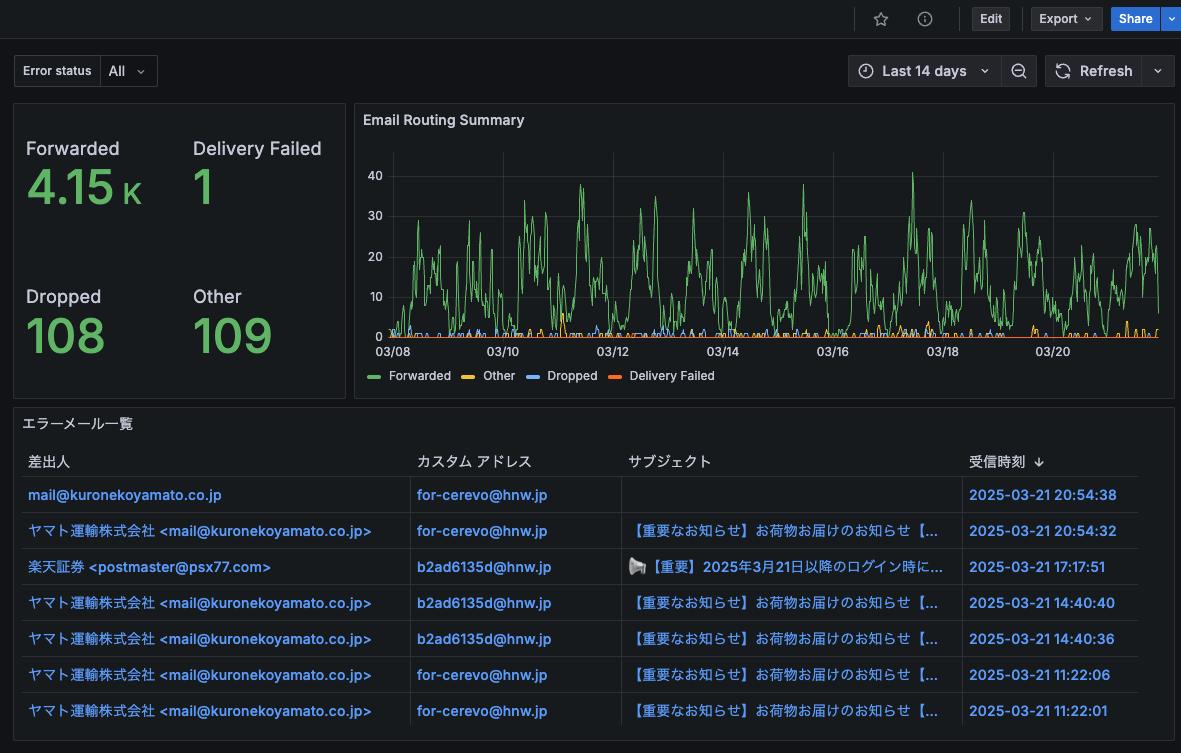
今回作ったものは下記になります。デプロイ手順等はREADMEをご確認ください。
また、Grafanaのダッシュボードも作りました。こちらもJSONの形でリポジトリに含まれており、コピペで利用できます。
システム構成
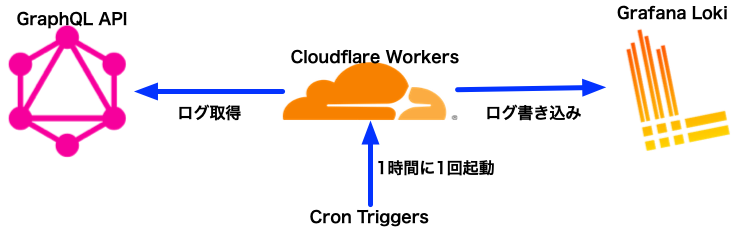
今回のログ転送の仕組みはCloudflare Workers上で動作するものです。これをCron Triggers経由で1時間に1回起動させています。いずれもCloudflareユーザーなら無料で使えます2 3。
ログの取得はGraphQL Analytics APIで行っています。Cloudflareの各種ログはGraphQL経由でユーザーに公開されており、Email Routingのログも自分でAPIを叩けば最大31日分取得できます4。
ログの保存にはGrafana CloudのLokiを利用しました。Grafana Cloudは開発元のGrafana Labsが提供しているフルマネージドのGrafana環境です。企業ユーザーが本番環境で使うなら有料プランになると思いますが、個人など小規模であれば無料で利用できます。
Lokiはログ集約・検索を担当するサービスです。Grafana Cloudの無料枠で50GB・14日間のログが保管されるため、私の不満点が解決できるというわけです。
Grafanaを使うメリット
今回の仕組みを作ってみて気づいたんですが、Grafanaは自分でダッシュボードを作れる点が圧倒的なメリットと言えます。
私の場合、転送失敗したメールが本当に問題がないかを確認したかったんですが、Cloudflareのダッシュボードだとパッと見でわかりにくいんですよね。Grafana ダッシュボードでメールサブジェクトも表示するようにしてみて、捨てても問題ないSPAMであることが一目瞭然になりました。
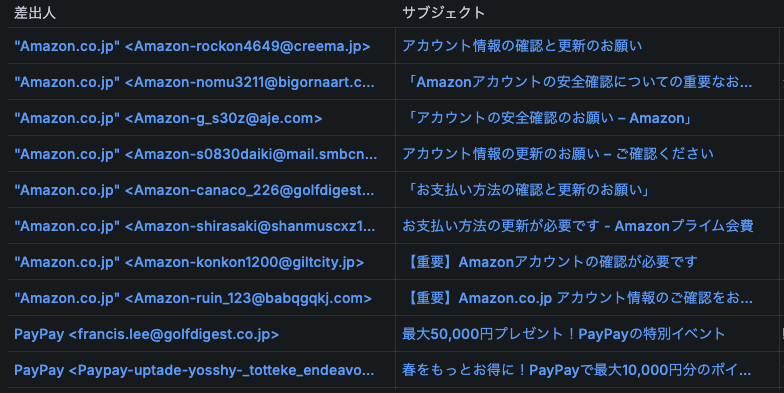
当然ですが、メールログをドリルダウンで辿るのもGrafanaの方が断然やりやすいですね。
一方で、Grafanaのダッシュボードはあまり直感的に作れない印象を持ちました。かなり複雑なデータ操作もGUIから設定できるんですが、冗長すぎて人間のやる作業ではないように思います。生成AIに頼むとそれっぽいJSONを作ってくれますが、学習量が足りないのかイマイチ参考になりませんでした5。
まとめ
- Cloudflare Email Routingのログを14日間確認できる仕組みを無料で構築できた
- Grafana Cloudは無料枠が大きくて素晴らしい
- Cloudflare Email RoutingはSPFやDMARCを根拠に転送エラーにするが、大半がSPAM
- 今回の仕組みがなくても大抵の人は困らないはず
- Grafanaはダッシュボードが自由に作れるのが強み
- ログやメトリクスをGrafanaに集約すると新たな気づきがあるかも
- 期間を指定するメニューに「Previous 7 days」という選択肢があるのですが、これを選ぶと内部的に呼び出しているGraphQLリクエストがエラーを返して機能しません。バグだと思うので、いずれ修正されるとは思います。↩
- Cloudflare Workersの無料枠は10万リクエスト/日です。1時間に1回実行した場合、無料枠の0.024%を消費することになります。↩
- Cron Triggersの無料枠は5です。すでに上限まで使っている場合は他Workerと相乗りして乗り切るか、Workers Paid Plan($5/月)プランの契約が必要になります。↩
- データセット名emailRoutingAdaptiveがメール転送のログです。保管期間についてはCloudflare GraphQL データセットの保管期間を確認するを参照しました。↩
- グラフィカルな設定をJSONで書けるのは生成AI向きなので、将来的には全部生成AIにやらせたいですね。↩