プログラムを書いていると、入力値が辞書に含まれているかを調べたいようなことがあります。たとえば、ユーザーに都道府県名を入力させて、それが正しい都道府県名であるかどうかを調べたい、というようなことがあるかもしれません。
このような内容をPHPで書く際、キーに都道府県名を持つような連想配列を作る習慣がある人は多いはずです。これは典型的な連想配列の使い方といえるでしょう。
<?php
$prefs = array(
"北海道" => true,
"青森" => true,
"沖縄" => true,
);
if (isset($prefs[$input])) {
}
一方で、in_array関数を使うやり方も考えられます。
<?php
$prefs = array(
"北海道",
"青森",
"沖縄",
);
if (in_array($input, $prefs)) {
}
突然ですが、クイズです。この2つのうち、どちらの方が良いコードでしょうか?
連想配列から特定のキーを持つ要素にアクセスするコストはO(1)であるのに対し、配列から特定の要素を探すコストはO(N)ですから、一般論としては連想配列を使う方が好ましいと言えるでしょう*1。しかし、計算量の議論はNが大きい場合には正しいですが、Nが小さい範囲では係数や定数項など他の要素の影響も無視できないはずです。常に前者の方が良いコードであると言えるだけの材料を我々は持っているのでしょうか。
そこで、今回PHP 5.6.30およびPHP 7.1.5を用いて、配列サイズとアクセス回数を変えながら両者の速度を測定してみました。本稿ではその結果を紹介します。
今回、配列と連想配列とで、辞書データの構築時間と検索時間の和を比較してみました。というのも、一定規模の配列になると構築にかかる時間も無視できないため、たとえ検索が遅くても構築が速い方がトータルでは有利になる可能性があるからです。
早速ですが、PHP 5.6.30での実験結果のグラフを示します。両対数グラフなので見方に注意してください。
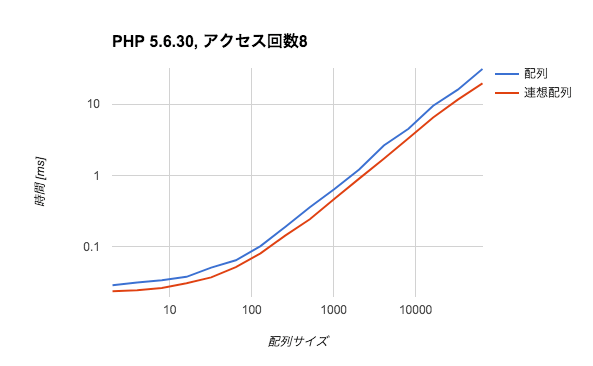
配列サイズというのは辞書に含まれる単語数です。また、アクセス回数というのはその辞書に対する検索の回数です。上記グラフではアクセス回数を固定して配列サイズを倍々で増やしていく、ということをしました。
これを見ると、アクセス回数が8回ある状況であれば連想配列の方が1.2から1.5倍程度は速いと言えそうです。また、アクセス回数128回になると差が絶望的に開きます。検索回数が多い場合は(当然ですが)検索の計算量の差が支配的であることがわかります。
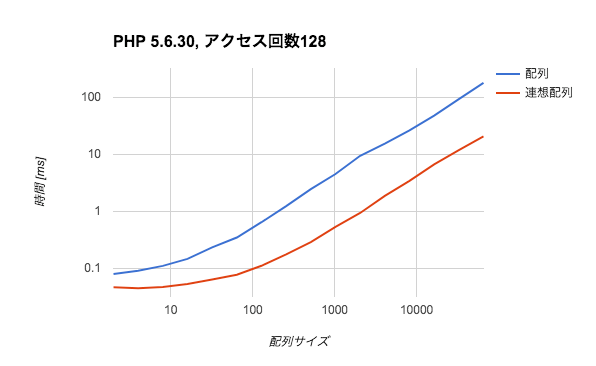
連想配列の方がデータの構築に時間がかかるためアクセス回数2回では互角程度になりますが、互角であれば連想配列を使った方が事故は少なそうです。
PHP 7系では配列アクセスに逆転されることがある
面白いことに、PHP 7系だと状況が変わってきます。PHP 7.1.5, アクセス回数8回のグラフを見てみましょう。
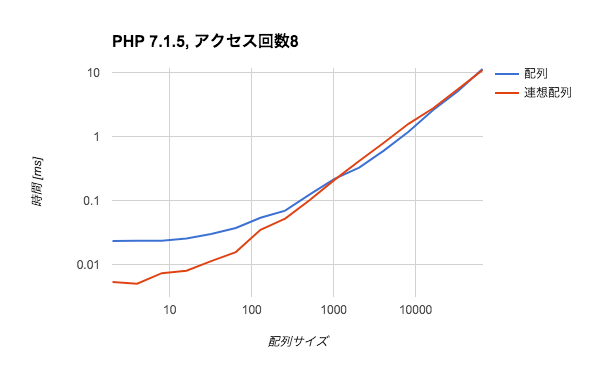
配列サイズが小さいうちは連想配列有利だったのが、配列サイズ2048あたりで配列が逆転し、サイズ65536あたりで連想配列が再逆転する、というような結果になっています。何が起こったのでしょうか。
配列サイズが小さいうちは配列と連想配列とで構築コストに大きな差はありません。この段階で差になってくるのは、in_array($key, $array)が関数呼び出しであるのに対し、isset($array[$key])はopcodeにコンパイルされて関数呼び出しにならないということです。PHPの関数呼び出しは他のopcode実行に比べるとコストが高いので、この差で連想配列の方が速くなっているのです。
配列サイズが中程度になってくると、配列と連想配列の構築コストの差が支配的になってきます。PHP 7からは真の配列と言うべきデータ構造が導入されており*2、連想配列と比べて簡潔なデータ構造で済むようになりました。このため、同じサイズであれば連想配列より配列の方が構築コストが低く、PHP 5のときは見られなかった逆転現象が起こるというわけです。
さらに配列サイズが大きくなってくるとO(N)とO(1)というアクセス時の計算量の差が効いてくるので、ふたたび連想配列の方が有利になります。
このように、アクセス回数8付近では複雑な状況が見られるわけです。一方、アクセス回数32であれば基本的には連想配列の方が有利となります。
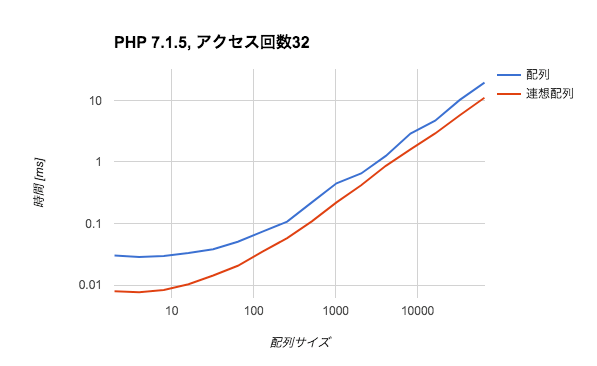
また、アクセス回数8192回では絶望的な差がついてきます。
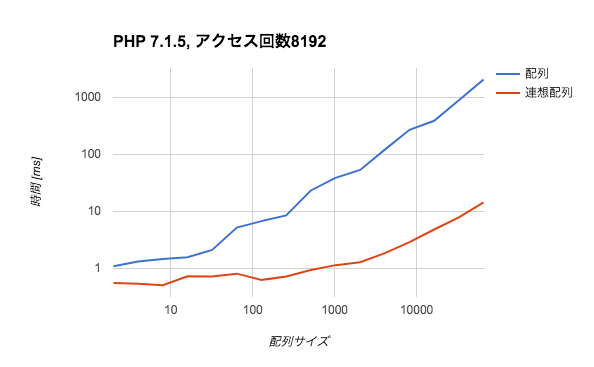
このように、アクセス回数が大きくなってくると予想通り連想配列の方が有利だということがわかります。
一方、アクセス回数が少ない場合に限れば配列を採用する可能性もゼロではないと言えそうです。とはいえ、プログラムの改修などでアクセス回数が増える可能性を考えると基本的には連想配列を採用しておく方が無難でしょう。
この文章をどう読むかについての補足(2017/5/25追記)
一般論として、普段のコーディングにおいてマイクロベンチの結果を参考にしすぎるのは良い習慣ではありません。たとえば、echoとprintfとでどちらが速い、みたいな内容に引っ張られて書くコードを変える必要はないでしょう。もしそれがボトルネックになっていることが判明したら、判明した後で変えれば良いはずです。
その一方で、マイクロベンチの速度差がなぜ生まれたのか、その原因を調べることで何らかの新しい知見を得ることもあるはずです。本稿で一番お伝えしたかったのは、その面白さについてでした。
加えて、今回は計算量の話題やオーダーの違いの怖さ、といった部分も盛り込んだわけですが、このあたりは人によって感覚が異なるのかもしれません。私個人の意見としては計算量の観点で不利な実装を採用する際は常に理由が必要だと思っており*3、本稿もそのような前提で書かれていますが、異なる意見があってもおかしくは無いと思います。
まとめ
PHPの連想配列と配列のin_array()とで、どちらが有利かを検討してみました。
- PHP 5.6では連想配列が有利
- PHP 7では「真の配列」のおかげで配列が有利な状況もありうる
- アクセス回数小、配列サイズ中程度の場合に限る
- 配列の方が検索コストは高いが、構築コストが低いため
- 現実には配列が正解という状況は少ないはず
- アクセス回数と配列サイズの両方が極端に少ない場合は配列の方が読みやすいかも
連想配列の方が有利だというのは特に驚きのない結論ですが、PHP 7の「真の配列」による性能向上が垣間見えたのは面白いと感じました。
ネイティブコードにコンパイルするような言語であれば、辞書サイズが小さいときは連想配列よりも配列が正解という状況もありうると思うんですが、PHPの場合はin_array()が関数呼び出しであることのペナルティが大きく、そのような状況は確認できませんでした。
追試用資料
筆者の手元のマシンはCore M採用のノートマシンであり、Turbo Boostのせいで結果が安定しなかったりするので、結果の信用性は保証できません。追試したいと思われた方は下記URLをご確認ください。

