PHPとPythonとRubyの連想配列のデータ構造がそれぞれ4〜5年ほど前に見直され、ベンチマークテストによっては倍以上速くなったということがありました。具体的には以下のバージョンで実装の大変更がありました。
- PHP 7.0.0 HashTable高速化 (2015/11)
- Python 3.6.0 dictobject高速化 (2016/12)
- Ruby 2.4.0 st_table高速化 (2016/12)
これらのデータ構造はユーザーの利用する連想配列だけでなく言語のコアでも利用されているので、言語全体の性能改善に貢献しています1。
スクリプト言語3つが同時期に同じデータ構造の改善に取り組んだだけでも面白い現象ですが、さらに面白いことに各実装の方針は非常に似ています。独立に改善に取り組んだのに同じ結論に至ったとすれば興味深い偶然と言えるでしょう2。
本稿では3言語の連想配列の従来実装と新実装の概要を説明した上で、新実装が速くなるカラクリについて私なりに解説してみます。
最初にお断りしておくと、斬新なハッシュ実装が発明されたような話ではありません。地道な改善と捉えた方が実状に近いと思います。
PHP・Python・Rubyの新旧実装の概要
各言語の連想配列のデータ構造がどう変わったのか見ていくことにしましょう。次の図はPHP5の連想配列のデータ構造です。

これはアルゴリズムの教科書にも載っているような連想配列の実装「チェイン法」の素直な実装になっています。キーに対応するハッシュ値を計算し、ハッシュ値ごとにキーと値の組を格納します。それぞれの値は連結リストで管理されています。
これを改善したものがPHP7の実装です。
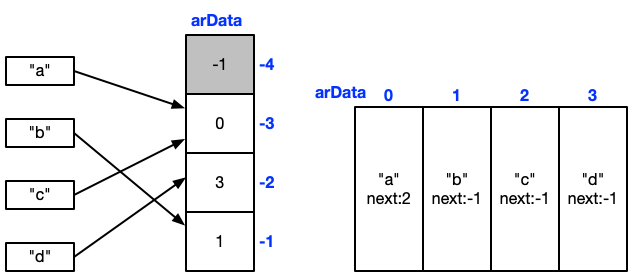
これはチェイン法の変形の実装と捉えることができます。前段の配列はPHP5ではポインタの配列でしたが、PHP7では添字の配列になりました。またキーと値の組はこれまで1要素ごとに動的に確保していたのをPHP7ではあらかじめ配列を確保した上で添字ベースで連結リストを実現しています。
次にPythonも見ていきましょう。Python 3.5までの連想配列の実装は次のようなものでした。
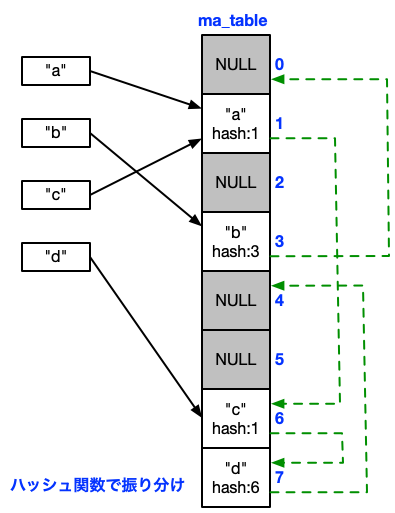
これまた教科書通りの連想配列の実装で、「オープンアドレス法」と呼ばれる方式です。データ構造としては配列1個のみのシンプルな仕組みですが、ハッシュ値が衝突した場合は決まったルールで要素を辿っていく必要があります。
Python 3.6ではこれに改善を加えています。

これはオープンアドレス法の変形になっており、添字を管理する配列と要素を管理する配列の2段構えになっています。衝突した場合のルールなどはPython 3.5以前と全く同じです。
Rubyについては旧実装がPHP5に近く、新実装はPython 3.6に似ているという認識です3。
なぜ速くなるのか?
PHP7とPython3.6の連想配列のデータ構造を見ると、データの持ち方が非常に似ているのがわかると思います。衝突解決の方針が異なっているだけで、2段構えの前段の配列で添字を管理する点、後段の配列は格納順に要素を追加していく点などは完全に同じです。
それにしても、なぜこれで速くなるのでしょうか。劇的に計算量が改善するような変更ではありませんし、Pythonについては間接参照が1回増えているので不利になってもおかしくありません。
性能改善は複数の要因が絡み合った結果でありアプリケーションにも依存するので、一概に「この点が性能改善に寄与した」とは言えないのですが、私は新実装のキモは次の2点だろうと考えています。
- データサイズの減少、メモリの参照局所性の向上
- 連想配列の構築時に連続するメモリ領域にシーケンシャルに書き込まれる点
要はメモリの読み書きに関連する改善が支配的だったのではないか?ということです。高級言語を使っているとつい忘れがちですが、現代のCPUから見るとメモリは非常に遅いのです。
キャッシュヒット率を高めた方が有利という話
メモリがCPUと比べてどれくらい遅いのか、Intelの資料4から読み取った数字を紹介します。
- L1キャッシュヒット 4 Clock
- L2キャッシュヒット 10 Clock
- L3キャッシュヒット 40 Clock
- キャッシュミス 200〜330 Clock
キャッシュミスが起こると数百クロックのメモリストールが発生するというのは恐ろしい数字ですよね。また、下位のキャッシュもまあまあ遅いことがわかります。ですから、現代のCPUではいかにキャッシュヒット率を高めるかが重要になります。扱うデータサイズを小さくできればその分メモリアクセスが減るはずですし、同時に使われるデータをできるだけ近くに格納すればキャッシュヒット率がアップするはずです5。
PHPについて言えば旧実装ではメモリ利用に無駄が多かったのが、新実装になって1要素あたりのメモリ使用量が半分以下になっています(72バイト→32バイト)。RubyもPHPほどではありませんが、ポインタアクセスを廃したことで特に64bit環境でメモリ使用量を削減できています6。またPythonはこれまでデータの隙間が多かった7のに対し、新実装では要素の配列を密に使えるようになり、サイズの小さい前段の添字配列だけが疎になるように変わっています。これらが性能改善に大きく貢献しているというのは直感的におかしくない話だと思います。
メモリのシーケンシャルアクセスは有利という話
改善要因の2点目に挙げた「連想配列の構築時に連続するメモリ領域にシーケンシャルに書き込まれる点」については補足が必要かもしれません。
古いプログラマ(私を含む)の常識として、連想配列は原則として格納順を保持しないというのがあると思います。しかし、今回紹介した新実装の後段、要素を格納する配列は添字の小さい方から順に使っていくことになるので、自然に実装すれば勝手に格納順が保持されます。これを利用してPython 3.7からは連想配列の要素の順序保持が仕様になっています。
私の意見は、この実装が機能面だけでなく性能面でもメリットを生んでいるのではないか?ということです。
Pythonの旧実装を考えると、複数の要素を持つ連想配列を構築する際のメモリ書き込みはランダムアクセスになっていました。一方、新実装ではシーケンシャルなアクセスになります。最近のCPUでは連続するメモリ領域のアクセスに対してハードウェアプリフェッチャーがよしなに働いてアクセスしそうなメモリ領域を勝手にキャッシュに乗せてくれるので、ランダムアクセスよりシーケンシャルアクセスの方が有利なのです。
スクリプト言語では言語コアでも連想配列を多用するため、連想配列の構築が頻繁に行われます。つまり、連想配列の構築コストを下げられれば性能面への寄与は大きいように思います。これがそこまで支配的な要因になるのかは正直なところわかりませんが、可能性としては十分ありうるように思います。
落穂拾い
今回スクリプト言語3つの連想配列の実装の経緯を調べてみたのですが、影響がゼロとは言えないにせよ、結果的に実装が似たような部分もありそうです。一方で、実装時期が近い点についてはOS・CPUの64bit化が関係しているかもしれません。2010年頃から64bit環境が一般的になって64bitポインタが性能面の足かせになるような状況が個別に表面化し、結果として同時期に改善されたというのはありうる話です(こうした因果関係は後から判断するのが難しい部分もありますが…)。
本稿では3言語の連想配列の実装が非常に似ているという話をしてきましたが、細かい点はかなり異なっています。PHPでは前段の添字を管理する配列に32bit整数を使っていますが、PythonとRubyでは連想配列のサイズが小さいときに添字を8bit整数の配列で管理してメモリ消費を抑える工夫が見られます。スクリプト言語では小さいサイズの連想配列を大量に使う傾向があるので、このような最適化は合理的なのでしょう。これはPHPでも採用の余地がありそうです。
連想配列の実装としてチェイン法とオープンアドレス法のどちらが優れているかについては何とも言えないところです。Rubyがチェイン法からオープンアドレス法に乗り換えているので、実はそちらの方が有望ということなのかもしれません。ただ、結果的にこれだけ似た実装になってしまうと両者で大差ないという可能性もありそうです。
落穂拾い2(追記:2020-01-11)
@_ko1さん(Rubyコアコミッター)から、「Ruby 2.4の実装時はPHPとPythonの実装を認識していた」とのこと。完全に独立な実装とは言えないようです。
これはrubyでは他言語を意識した変更です https://t.co/YKQzTajqCc
— _ko1 (@_ko1) January 10, 2021
確かに、当時の議論を確認するとPythonの旧実装をかなり参考にしてますね。ただ、Python 3.6とほぼ同時期に実装が行われているので、偶然の一致の部分も多少ありそうに思いました。
@methaneさん(Pythonコアコミッター、Python 3.6のdict改善の実装者)から、「Python 3.6の変更は挿入順の維持が主目的、メモリ使用量削減はメリットだが性能面ではそこまで大きなインパクトはないかも」とのこと。
やっぱり訂正。主目的は、「挿入順の維持を旧dictに対してオーバーヘッドがほとんどないように実現する」と言った方が背景として正確でした。
— Inada Naoki (@methane) January 11, 2021
おまけでメモリ使用量削減、生成とイテレートの高速化がついてくるからお得。 https://t.co/oYbpbDGv0j
ごめんなさい、タイトルが嘘でしたね…。確かにPythonの旧実装は余計なポインタ参照もないので64bit環境でも不利じゃないよなーとは思ってました。
まとめ
PHP、Python、Rubyの連想配列の性能およびメモリ効率が2015〜2016年ごろに改善され、それらの実装が似ているという話を紹介しました。また、性能改善の要因はメモリの読み書きに関連するものではないか?という私の意見を紹介しました。
3つの実装が似ているという指摘はあまり見たことがないので記事にまとめてみましたが、他の言語でもこれを真似すべき、という話をしたいわけではありません。3言語とも各言語を使ったベンチマークテストを実施した上で新実装を採用したわけで、これが別の言語・別のアプリケーションでも最適なデータ構造とは限りません。大事なのは「推測するな、計測せよ」ですよね。
性能改善の要因については私の妄想の部分も多分にあると思いますし、PythonとRubyについては今回ざざっとソースコードを眺めた程度なので致命的な間違いがあるかもしれません。識者の方のツッコミをお待ちしております。
参考URL
-
https://github.com/ruby/ruby/blob/master/st.c のコメント部に新実装の説明が書いてありました↩
-
Performance Analysis Guide for Intel® Core™ i7 Processor and Intel® Xeon™ 5500 processorsより↩
-
メモリキャッシュは64バイトなどのキャッシュラインサイズ単位でキャッシュされるため、1バイトアクセスしたら周囲の64バイトのアクセスもタダみたいなもんです↩
-
Ruby2.3以前は要素のチェインを双方向連結リストで管理していた点も不利だったように思います↩
-
オープンアドレス法では衝突頻度を下げるためにハッシュテーブルサイズを大きめに取る必要があり、教科書的実装だとメモリを飛び飛びに使うことになるため↩